Analyse de cluster: Définition, types et exemples
Résumez avec
L'analyse de cluster est un outil simple et efficace à utiliser dans l'environnement des affaires. Il aide à mieux comprendre les données quantitatives ou parfois qualitatives compliquées avec des méthodes de modélisation détaillées. Contrairement à d'autres types d'analyses, son objectif principal n'est pas de montrer ou de prouver des raisons; c'est un outil auxiliaire pour mieux révéler ce qui se passe.
Dans cet article, pour examiner en profondeur l'analyse de cluster, ce qu'est l'analyse de cluster sera la première chose à expliquer. Ensuite, il sera expliqué quels méthodes/types vous pouvez utiliser pour mener cette analyse. Enfin, vous pouvez obtenir des informations plus précises dans la section des questions fréquemment posées.
Qu'est-ce que l'analyse de cluster?
L'analyse de cluster est une méthode de traitement de données multivariée utilisée pour montrer des statistiques. Son objectif est de catégoriser ou, en d'autres termes, de regrouper des entités.
Elle sert de phase fondamentale et pivot dans l'analyse statistique des données ainsi que dans l'exploration de données. Mais il est également possible de l'utiliser dans différents domaines. En particulier, l'analyse de cluster dans l'exploration de données peut spécifier des caractéristiques qualitatives et quantitatives, montrant ainsi sa flexibilité. C'est pourquoi les entreprises utilisent toujours l'analyse de cluster comme partie de leur mécanique de prise de décision.
L'algorithme de l'analyse de cluster est assez simple. Il crée des motifs visibles en regroupant des entités similaires. Cependant, avec cette caractéristique, il est loin d'être un type d'analyse détaillé. D'un autre côté, fournir des données précises a également une place importante ici.
Plus les données sont adaptées au regroupement, plus un modèle de regroupement efficace est formé. Il serait donc judicieux de choisir les méthodes et les programmes les plus adaptés à votre objectif lors de la réalisation d'une analyse de cluster.
Types d'analyse de cluster
Choisir le bon algorithme de clustering peut être un peu comme un essai et erreur. Mais s'il y a une raison mathématique solide pour jurer par l'un plutôt que par les autres, alors cela peut être raisonnable. Et l'important ici est que ce qui peut fonctionner comme par magie pour un ensemble de données peut tomber à plat avec un autre.
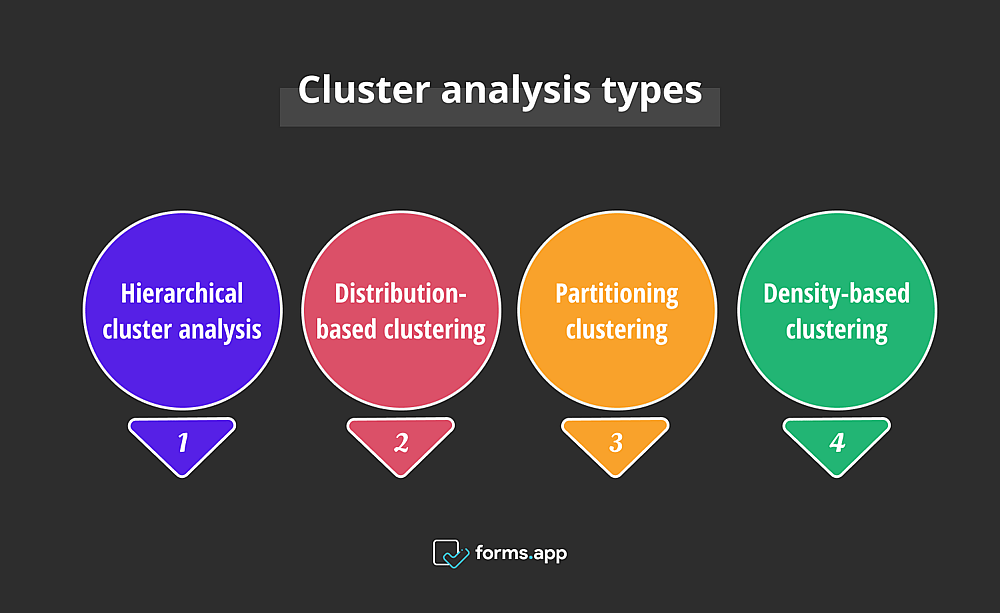
Une variété de méthodes d'analyse de cluster ci-dessous vous sont présentées, chacune apportant son aspect et son approche uniques à la table. C'est comme choisir le bon outil pour le travail et découvrir celui qui fonctionne avec votre ensemble de données. Maintenant, les quatre types les plus connus vous sont présentés avec des exemples d'analyse de cluster:
Types d'analyse de cluster
Analyse de cluster hiérarchique
Dans cette méthode, l'algorithme organise la classification des entités de données fournies dans un ordre hiérarchique. La formation de clusters se produit en commençant par un cluster unique et en le divisant en clusters séparés.
L'ordre de la hiérarchie entre ces clusters peut varier en fonction de l'objectif de votre classification et de votre méthode de modélisation. Vous pouvez utiliser principalement deux approches différentes pour le cluster hiérarchique:
- Méthode agglomérative: C'est un processus ascendant qui commence par une seule entité et crée des groupes de clusters à partir de celle-ci.
- Approche divisée: C'est un processus descendant qui commence par des entités dans le même cluster et crée des groupes de clusters en les divisant.
#Exemple d'analyse de cluster hiérarchique
Imaginez une entreprise technologique lançant un nouveau dispositif de maison intelligente. L'entreprise souhaite utiliser l'analyse de cluster hiérarchique pour comprendre comment les clients potentiels réagiront à ce nouveau produit. Des données telles que l'âge, le revenu, le niveau d'éducation, etc. des clients sont collectées pour l'analyse.
L'analyse hiérarchique commence à créer des clusters en conséquence. Par exemple, un cluster tel que les jeunes et ceux ayant de hauts revenus est formé, et ce groupe peut être exactement le public cible que vous recherchez.
Clustering basé sur la distribution
Ce modèle de clustering montre la distribution des entités de données interconnectées sur le graphique. Les Modèles de Mélange Gaussien en sont un exemple typique. Son domaine d'utilisation est de regrouper plus facilement des structures complexes connectées les unes aux autres.
#Exemple de clustering basé sur la distribution
Supposons qu'une entreprise fournisseur d'internet souhaite comprendre les modèles d'attrition des clients pour y intervenir. Tout d'abord, il devrait y avoir un ensemble de données comprenant des informations telles que satisfaction générale ou spécifique des clients, préférences de forfait internet, frais d'engagement et réponses.
Ensuite, vous utilisez l'algorithme de clustering basé sur la distribution et attendez qu'il révèle le modèle entre ces valeurs. Par exemple, si le taux de vente est faible dans un groupe qui est contacté souvent pour renouveler les engagements internet, cela et des modèles similaires constituent un exemple d'attrition actuelle et future.
Clustering par partitionnement
Contrairement au clustering basé sur la distribution, le partitionnement divise les entités de données en sections non-chevauchantes. Ainsi, chaque partie qu'il divise devient un cluster. Ces clusters peuvent être utilisés pour les séparer les uns des autres pour un objectif spécifique. Pour mettre en œuvre un partitionnement comme celui-ci, la méthode K-Means est la plus couramment utilisée.
- Clustering K-means: Le clustering K-means trie votre ensemble de données en clusters prédéterminés. L'algorithme place aléatoirement des centres de cluster et commence à trier les entités de données autour de ces centres. Ensuite, la moyenne de ces centres est prise, et un nouveau centre est créé. Ce processus peut être répété plusieurs fois, ce qui donne des clusters non chevauchants.
#Exemple de clustering par partitionnement
Imaginez un magasin dans un scénario de vente au détail ayant du mal avec sa stratégie de marketing. Opter pour le clustering par partitionnement est la première étape de la recherche de marché. Les algorithmes d'apprentissage automatique identifieront des clusters tels que des groupes de clients et des segments de marché selon des partitions prédéfinies.
Les modèles de base de clients résultants aideront l'entreprise à prendre de meilleures initiatives envers le marché cible. Par exemple, si le magasin a un profil de client à fort pouvoir d'achat, il peut renforcer son marketing en proposant des programmes de fidélité et des promotions à ce groupe de clients.
Clustering basé sur la densité
Le clustering basé sur la densité révèle des groupes similaires en identifiant la densité des points de données. Sa différence distincte par rapport aux autres types est qu'il évite de créer des clusters d'une certaine forme ou taille plutôt que de créer un certain nombre de clusters. À cet égard, il est utile dans les cas où les entités de données ont un ordre irrégulier lors de la formation d'un cluster.
#Exemple de clustering basé sur la densité
Supposons qu'une entreprise essaie d'ouvrir de nouveaux magasins et veut identifier les points chauds des clients. Elle souhaite améliorer la qualité du nouveau magasin de détail en utilisant un algorithme de clustering basé sur la densité.
L'algorithme peut identifier les emplacements de choix en distinguant les zones avec un flux intense de clients, les démographies de la population et les attitudes d'achat de cette population. De cette façon, les propriétaires d'entreprise disposent de données précieuses qu'ils peuvent utiliser lors de la prise de décisions concernant l'ouverture du magasin.
Questions fréquemment posées sur l'analyse de cluster
Les questions les plus fréquemment posées sur l'analyse de cluster concernent le moment et la manière d'utiliser quelle méthode de clustering. Les nouveaux utilisateurs peuvent parfois rencontrer une confusion concernant l'interprétation des clusters. C'est pourquoi les questions recueillies ici visent à démêler efficacement d'importants nuances d'interprétation et à vous préparer pour l'analyse des données.
Les quatre types d'analyse de cluster les plus courants sont l'analyse de cluster hiérarchique, le clustering de distribution, le clustering de partitionnement et le clustering basé sur la densité. Bien qu'ils aient tous plus ou moins le même objectif, leurs processus de regroupement sont différents les uns des autres.
Il est vrai qu'à première vue, l'analyse en grappes apparaît comme un type d'analyse quantitative, mais des algorithmes performants et des ensembles de données bien préparés montrent qu'elle peut également être utilisée dans le cadre d'une analyse qualitative.
Non, l'échantillonnage en grappes et l'analyse en grappes ne sont pas identiques. L'échantillonnage en grappes est un processus utilisé dans la phase de collecte des données. Il permet d'échantillonner un grand groupe de populations de manière aléatoire. Il n'est pas obligatoire dans l'analyse en grappes. En revanche, l'analyse de grappes est une méthode d'analyse des données qui permet d'identifier des modèles similaires et de les regrouper.
Les cartes auto-organisatrices, les méthodes basées sur les graphes et les méthodes basées sur les grilles sont également des méthodes intéressantes que vous pouvez utiliser pour la reconnaissance des formes de grappes.
Comme on le sait, l'analyse en grappes ne recueille pas de données. Elle crée plutôt un modèle utile en divisant vos données en morceaux et en les regroupant à l'aide de l'algorithme de regroupement. Par conséquent, vous devez préparer vous-même les données pour l'analyse en grappes et prêter attention à certains facteurs.
- Tout d'abord, trouvez les données qui conviennent à votre objectif et créez une base de données complète et détaillée.
- Standardisez les données en fonction de l'échelle sur laquelle vous les évaluerez.
- Adaptez vos données au programme de classification que vous utiliserez.
- Enfin, demandez au programme de classer les données à l'aide de l'algorithme de regroupement.
L'analyse des résultats des regroupements est aussi importante que la création et le traitement des données. Vous pouvez inspecter visuellement les groupes (colorés, groupés ou en forme) grâce à la facilité offerte par la modélisation. L'étape suivante consiste à évaluer les données numériques en fonction de la méthode par laquelle vous avez créé votre modélisation.
Vous déterminez ainsi les caractéristiques de chaque groupe. Si vos données contiennent également des caractéristiques qualitatives, n'oubliez pas d'évaluer les relations entre les modèles en conséquence. Grâce à ces étapes d'analyse, vous serez en mesure d'utiliser l'analyse en grappes pour votre processus de prise de décision.
Conclusion
Dans l'ensemble, l'analyse de cluster montre sa puissance pour révéler des modèles en utilisant différentes techniques de modélisation. Sa haute dimensionnalité est un aspect fort de celle-ci. Cet article essaie de montrer avec des exemples que l'analyse de cluster en marketing et en exploration de données est bénéfique pour les entreprises. Qu'il s'agisse d'informations qualitatives ou de prédictions quantitatives, l'analyse de cluster révèle la relation entre elles grâce à une puissante exploration de données.
C'est-à-dire que les entreprises modernes bénéficient de ce type d'analyse pour suivre les tendances et révéler des corrélations qui ne sont pas visibles au premier coup d'œil. Vous devriez donc comprendre et tirer profit de l'analyse de cluster pour améliorer votre entreprise dans un monde où les données sont aussi précieuses que l'or.
Contributeurs
Recherché et rédigé par
forms.app, ton créateur de formulaires gratuit
- Nombre illimité de vues
- nombre illimité de questions
- nombre illimité de notifications
Articles connexes

Un guide complet des méthodes d'analyse de données
Arbres de décision: Définition, types et exemples
Analyse factorielle : Un guide complet
Réseaux neuronaux et comment les utiliser dans l'analyse de données
Analyse de régression : Définition, types et exemples