Was ist die Stichprobenfehler? (Definition, Typen & mehr)
Fasse zusammen mit
Sie haben einige Recherchen durchgeführt, aber es gibt einige Probleme. Die Ergebnisse waren nicht wie erwartet. Sie dachten jedoch, dass Sie alles richtig gemacht haben. Was ist also genau der Grund dafür? Könnte es einen Stichprobierfehler geben?
Wenn Sie nach dem Stichprobierfehler fragen, beeilen Sie sich nicht, denn er wird im Rest des Artikels ausführlich erklärt, aber wissen Sie so viel: Der Stichprobierfehler ist etwas, mit dem jeder im Bereich der Analyse vertraut ist, und Sie müssen sich leider damit auseinandersetzen.
Beginnen wir von vorne: Was ist der Stichprobierfehler?
Ein Stichprobierfehler ist ein Forschungsproblem, das entsteht, wenn eine untersuchte Population nicht die gesamte Bevölkerung widerspiegelt.
Der Hauptgrund für diesen Standardfehler ist, dass die Stichprobe der Bevölkerung in Bezug auf Vielfalt und Anzahl nicht mit der tatsächlichen Bevölkerung kompatibel ist. Obwohl Forscher eine Fehlermarge in ihre Forschung einbeziehen, ist der Stichprobierfehler immer ein Problem, mit dem sie umgehen müssen.
Stichprobierfehlerarten in der Marktforschung
Unternehmen greifen oft auf Analysen zurück, um sich in eine bessere Position zu bringen. Wenn diese Analysen jedoch nicht sorgfältig durchgeführt werden, können sie einige Ungenauigkeiten verursachen, wie zum Beispiel Stichprobierfehler. Die am häufigsten beobachteten Arten von Stichprobierfehlern sind unten aufgeführt:
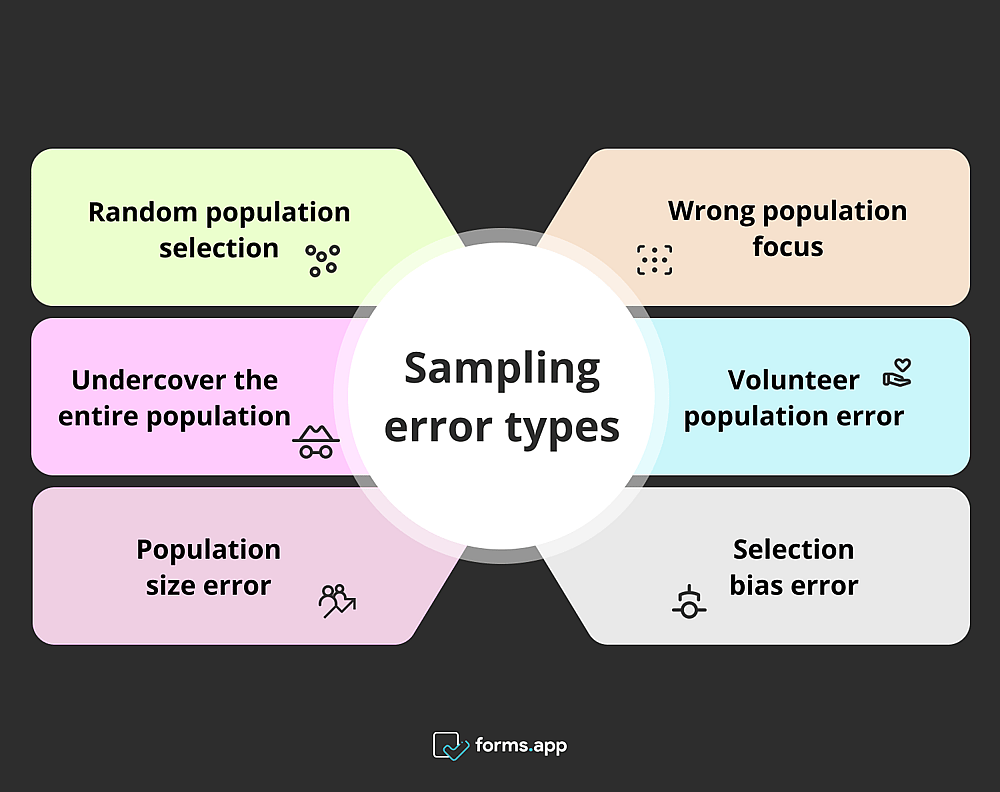
Stichprobierfehlerarten in der Marktforschung
- Zufällige Auswahl der Bevölkerung: Eine zufällige Auswahl der Bevölkerung kann Raum für Fehler lassen, da dies bedeutet, die Forschung vollständig dem Zufall zu überlassen. Wenn Sie dies jedoch systematisch tun, wird es als systematische Stichprobe bezeichnet, was eine anständige Technik ist.
- Falscher Fokus auf die Bevölkerung: Dieser Fehler tritt auf, wenn die Forscher eine Bevölkerung auswählen, von der sie glauben, dass sie für die Forschung geeignet ist, die aber für den Zweck der Forschung irrelevant ist.
- Die gesamte Bevölkerung undercover: Zum Beispiel bedeutet die Durchführung einer Umfrage im Internet, die Bevölkerung zu ignorieren, die das Internet nicht nutzt oder nicht nutzen kann.
- Freiwilligen-Bevölkerungsfehler: Wie die zufällige Auswahl der Bevölkerung, sind auch Freiwilligengruppen bekannt dafür, die Ergebnisse der Forschung negativ zu beeinflussen.
- Bevölkerungsgrößenfehler: Die Stichprobengröße muss je nach Schwerpunkt der Forschung groß oder klein gehalten werden. Wenn die Forscher dieses Gleichgewicht nicht aufrechterhalten, werden sie auf falsche Ergebnisse stoßen.
- Auswahlverzerrungsfehler: Dieser Fehler tritt auch auf, wenn der Forscher die Bevölkerung zugunsten der Forschung auswählt, um die Forschungshypothese zu beweisen. Diese Methode spiegelt also nicht die Realität wider.
Beispiel für den Stichprobenfehler
Ein Beispiel für einen Stichprobenfehler wird hier gegeben. Zunächst sollten Sie jedoch wissen, wie man den Stichprobenfehler berechnet. Sie können im Allgemeinen Analyseprogramme und künstliche Intelligenz als Stichprobenfehlerrechner verwenden, aber es kann trotzdem nützlich sein, die Stichprobenfehlerformel zu kennen.
Stichprobenfehler = Z x STD/Sqrt (N)
Z- ist der z-Wert, der dem gewünschten Konfidenzniveau entspricht (1,96 für ein Konfidenzniveau von 95%).
STD- ist die Standardabweichung der Bevölkerung.
N- ist die Stichprobengröße.
Zum Beispiel zielt die Marktforschung darauf ab, die Anzahl der Menschen zu erreichen, die im Sommer Hüte tragen. Dafür führt ein Unternehmen eine Umfrage durch, um den Anteil der Menschen zu schätzen, die regelmäßig im Sommer Hüte tragen, in einer kleinen Stadt. Sie haben eine zufällige Stichprobe von 400 Personen ausgewählt und festgestellt, dass 120 von ihnen angaben, regelmäßig im Sommer Hüte zu tragen. Die Forscher verwendeten die obige Formel, um die Fehlertoleranz zu berechnen.
Die Fehlertoleranz für den geschätzten Anteil der Menschen, die während der Sommersaison Hüte tragen, beträgt etwa 0,0448. Dies bedeutet, dass mit einer 95%igen Konfidenz der wahre Anteil der Hutträger in der Bevölkerung wahrscheinlich innerhalb von 4,48 Prozentpunkten des beobachteten Anteils (30%) liegt, der aus der Stichprobe gewonnen wurde.
Abweichungsfehler vs. Nicht-Abweichungsfehler
Abweichungsfehler sind nicht die einzigen statistischen Fehler, die in der Forschung auftreten; es gibt auch Nicht-Abweichungsfehler. Beide beeinflussen das Ergebnis der Forschung negativ. Was sind also genau die Unterschiede zwischen diesen beiden?
- Abweichungsfehler werden durch Probleme verursacht, die nur mit den falschen Bevölkerungsparametern der Forschung zusammenhängen.
- Diese treten oft aufgrund von Forschungsverzerrung, Messfehler, und fehlerhafter oder zufälliger Stichprobenziehung auf.
- Nicht-Abweichungsfehler werden durch andere Teile der Forschung verursacht. Es gibt mehrere Arten davon, da es verschiedene Fehler gibt, je nachdem, ob die Forschung in Teilen wie Datenerhebung, Datenanalyse, und Dateninterpretation erfolgt.
- Beispiele für Nicht-Abweichungsfehler sind in der Regel Probleme wie Mangel oder Ungenauigkeit von Daten, Inkonsistenz der Analyse oder problematische Kodierung, falsches Design der Umfrage oder mangelhafte Qualität der Fragen.
Wie man den Abweichungsfehler minimiert
Damit die Forschung präzise und zuverlässige Ergebnisse liefert, muss die Fehlertoleranz ziemlich gering sein. Diese Fehlertoleranz wird im Allgemeinen zwischen 5% und 3% als akzeptabel angesehen. Wenn Sie also eine Umfrage wiederholen, sollte das Ergebnis mehr oder weniger dasselbe sein. Andernfalls kann es zu einem Abweichungsfehler usw. kommen. Wie sollten Sie also Vorsichtsmaßnahmen gegen diesen Fehler treffen?

Wie man den Abweichungsfehler reduziert
- Erhöhung der Stichprobengröße: Je größer eine Population ist, die eine Studie abdeckt, desto näher kommt sie der Realität. Denn eine kleine Stichprobengröße hat viele Nachteile und verursacht daher Fehler. Die Hauptnachteile davon sind Unfähigkeit, Unterschiede zwischen Gruppen zu bestimmen, Forscherverzerrung, und Verallgemeinerungsfehler.
- Cluster-Stichproben: Die Einteilung der Zielbevölkerung der Forschung in Gruppen ermöglicht es, sie leichter zu klassifizieren und die richtigen Fragen zu stellen. Dies ist sehr nützlich, da es nicht nur eine praktische Lösung ist, sondern auch als kostengünstige Lösung bekannt ist.
- Vertrautheit mit der Bevölkerung: Es ist für Forscher wichtig, über Vorwissen über die Bevölkerung zu verfügen, die Gegenstand der Forschung ist. Dies stellt sicher, dass die Forschung frei von zufälligen oder unregelmäßig vorbereiteten Umfragefragen ist. Es verbessert auch die Leistung der Analyse im Allgemeinen, indem es eine bessere Auswertung der Ergebnisse ermöglicht.
- Pilot-Test: Schließlich können Sie eine Forschung in einer kleinen Gruppe oder Region pilotieren. Natürlich kann dies ein Ergebnis zeigen, das weit vom Ergebnis der Forschung entfernt ist, aber Sie können diese Methode nutzen, um den Zweck und die Methode Ihrer Forschung klar zu bestimmen und potenzielle Probleme im Voraus zu lösen.
Häufig gestellte Fragen zum Stichprobenfehler
In diesem Abschnitt können Sie leicht finden, was Sie interessiert und mehr über den Stichprobenfehler erfahren möchten.
In der Biologie liegt ein Stichprobenfehler vor, wenn Proben von lebenden Organismen, Geweben oder Zellen nicht mit den Merkmalen der allgemeinen Bevölkerung übereinstimmen. Diese Unstimmigkeit wird durch eine falsche oder unvollständige Auswahl der Proben verursacht. Die Verringerung des Stichprobenfehlers ist ein Muss, damit biologische statistische Analysen erfolgreicher sind.
Ein Fehler ist, wie der Name schon sagt, eine unerwünschte Situation. Er wirkt sich negativ auf die Qualität jeder Forschung aus. Zunächst einmal führt er dazu, dass Vorhersagen und Berechnungen ungenau und unvollständig sind. Dadurch verringert er die Genauigkeit der Ergebnisse. Er führt zu Zeit- und Geldverlust, da die Forschung erneut abgetastet und bearbeitet werden muss.
Die Vermeidung von Stichprobenfehlern ist eigentlich recht einfach. Sie brauchen dafür kein umfangreiches Wissen, Sie müssen nur Folgendes beachten.
Halten Sie den Umfang der Stichprobe stets groß
Vermeiden Sie homogene Gruppen und wenden Sie kontrollierte Zufallsstichproben an.
Legen Sie Ihren Forschungsschwerpunkt und den Stichprobenrahmen gut fest
Führen Sie Pilotstudien durch
Holen Sie sich die Hilfe von Statistikexperten
Stellen Sie sicher, dass die Untersuchung jederzeit valide ist.
Stichprobenfehler sind im Großen und Ganzen das Ergebnis einer oberflächlichen Forschung und eines unerfahrenen Forschers. Um diese Gründe näher zu erläutern: Der Verlauf der Untersuchung wird dem Zufall überlassen, die Zielgruppen werden nicht geclustert oder die Stichprobengröße wird klein gehalten, die Untersuchung wird ohne jegliche Methodik und Aufzeichnung fortgesetzt, Analysetechniken werden nicht ordnungsgemäß angewandt, und es werden falsche Daten erhoben.
Abschließende Worte
Als Ergebnis sind Stichprobenfehler irreführende Fehler bei der Datensammlung und -analyse für die Zielbevölkerung. Sie müssen dies vermeiden, damit Ihre Forschung genaue Ergebnisse liefern kann.
Dieser Artikel erklärt die Definition und Arten von Stichprobenfehlern anhand von Beispielen. Es zeigt auch die Formelberechnung, die Sie für den Stichprobenfehler verwenden können. Sein Unterschied zum Nicht-Stichprobenfehler und wie Sie den Stichprobenfehler minimieren können, wird erklärt. Somit haben Sie nun mehr Informationen über den Stichprobenfehler.
Mitwirkende
forms.app, dein kostenloser Formulargenerator
- Unbegrenzte Ansichten
- unbegrenzte Anzahl von Fragen
- unbegrenzte Benachrichtigungen
Ähnliche Beiträge

Datenanalyse: Arten, Methoden & Beispiele

Wettbewerbsanalyse: Definition, Durchführung & Beispiele
