Análisis de clúster: Definición, tipos y ejemplos
Resume con
El análisis de clusters es una herramienta simple y efectiva para utilizar en el entorno empresarial. Ayuda a comprender mejor datos cuantitativos o, a veces, cualitativos complicados con métodos de modelado detallados. A diferencia de otros tipos de análisis, su principal objetivo no es mostrar o probar razones; es una herramienta auxiliar para revelar mejor lo que está sucediendo.
En este artículo, para examinar el análisis de clusters en profundidad, lo primero que se explicará es qué es el análisis de clusters. Luego, se explicará qué métodos/tipos puedes utilizar para realizar este análisis. Finalmente, puedes obtener información más precisa de la sección de preguntas frecuentes.
¿Qué es el análisis de clusters?
El análisis de clusters es un método de procesamiento de datos multivariado utilizado para mostrar estadísticas. Su objetivo es categorizar o, es decir, agrupar entidades.
Sirve como una etapa fundamental y crucial en el análisis estadístico de datos, así como en la minería de datos. Pero también es posible utilizarlo en diferentes áreas. En particular, el análisis de clusters en la minería de datos puede especificar tanto características cualitativas como cuantitativas, lo que muestra su flexibilidad. Por eso, las empresas siempre utilizan el análisis de clusters como parte de su mecánica de toma de decisiones.
El algoritmo del análisis de clusters es bastante simple. Crea patrones visibles agrupando entidades similares juntas. Sin embargo, con esta característica, está lejos de ser un tipo de análisis detallado. Por otro lado, proporcionar datos precisos también tiene un lugar importante aquí.
Cuanto más adecuados sean los datos para el agrupamiento, más efectivo será el patrón de agrupamiento formado. Por lo tanto, sería una buena idea elegir los métodos y programas más adecuados para tu objetivo al realizar el análisis de clusters.
Tipos de análisis de clusters
Elegir el algoritmo de clustering adecuado puede ser un poco como prueba y error. Pero si hay una sólida razón matemática para confiar en uno sobre los demás, entonces puede ser razonable. Y lo importante aquí es que lo que puede funcionar como magia para un conjunto de datos puede fallar con otro.
A continuación se presentan una variedad de métodos para el análisis de clusters, cada uno aportando su aspecto y enfoque único. Es como elegir la herramienta adecuada para el trabajo y descubrir cuál funciona con su conjunto de datos. Ahora, se presentan los cuatro tipos más conocidos de análisis de clusters con ejemplos:
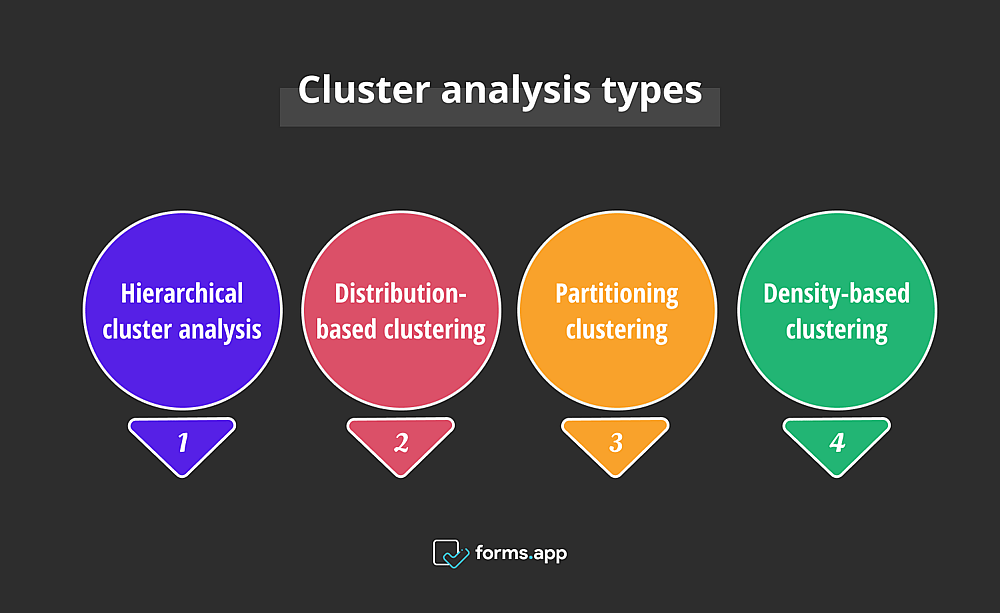
Tipos de análisis de clusters
Análisis de clusters jerárquico
En este método, el algoritmo ordena la agrupación de las entidades de datos proporcionadas en un orden jerárquico. La formación de clusters ocurre comenzando desde un solo cluster y dividiéndolo en clusters separados.
El orden de la jerarquía entre estos clusters puede variar dependiendo del propósito de su clasificación y su método de modelado. Puede utilizar principalmente dos enfoques diferentes para el análisis de clusters jerárquicos:
- Método aglomerativo: Es un proceso de abajo hacia arriba que comienza con una sola entidad y crea grupos de clusters a partir de ella.
- Enfoque divisivo: Es un proceso de arriba hacia abajo que comienza con entidades en el mismo cluster y crea grupos de clusters dividiéndolos.
#Ejemplo de análisis de clusters jerárquico
Imaginemos una empresa tecnológica que lanza un nuevo dispositivo para el hogar inteligente. La empresa quiere utilizar el análisis de clusters jerárquico para comprender cómo los posibles clientes responderán a este nuevo producto. Se recopilan datos como edad, ingresos, nivel de educación, etc., para su análisis.
El análisis jerárquico comienza a crear grupos en consecuencia. Por ejemplo, se forma un grupo como jóvenes y aquellos con altos ingresos, y este grupo puede ser exactamente el público objetivo que estás buscando.
Agrupación basada en la distribución
Este modelo de agrupación muestra la distribución de entidades de datos interrelacionadas en el gráfico. Los Modelos de Mezcla Gaussiana son un ejemplo típico de este tipo. Su área de uso es para agrupar estructuras conectadas entre sí con estructuras complejas con mayor facilidad.
#Ejemplo de agrupación basada en la distribución
Supongamos que una compañía proveedora de internet quiere entender los patrones de cancelación de clientes para intervenir en ello. En primer lugar, debe haber un conjunto de datos que incluya información como satisfacción general o específica del cliente, preferencias de paquetes de internet, tarifas de compromiso y respuestas.
Luego, se utiliza el algoritmo de agrupación basado en la distribución y se espera que revele el patrón entre estos valores. Por ejemplo, si la tasa de ventas es baja en un grupo que se contacta mucho para renovar compromisos de internet, esto y patrones similares constituyen un ejemplo de cancelación actual y futura.
Agrupación por particionamiento
A diferencia de la agrupación basada en la distribución, el particionamiento divide las entidades de datos en secciones no-superpuestas. Así, cada parte que divide se convierte en un grupo. Estos grupos pueden ser utilizados para separarse entre sí para un propósito específico. Para implementar un particionamiento como este, se utiliza más comúnmente el método K-Means.
- Agrupación K-Means: La agrupación K-means ordena tu conjunto de datos en grupos predefinidos. El algoritmo coloca aleatoriamente centros de grupo y comienza a ordenar entidades de datos alrededor de estos centros. Luego, se toma el promedio de estos centros y se crea un nuevo centro. Este proceso puede repetirse muchas veces, dando como resultado grupos no superpuestos.
#Ejemplo de agrupamiento por partición
Imagina una tienda en un escenario de venta al por menor que tiene dificultades con su estrategia de marketing. Optar por el agrupamiento por partición es el primer paso en la investigación de mercado. Los algoritmos de aprendizaje automático identificarán grupos como grupos de clientes y segmentos de mercado según las particiones predefinidas.
Los patrones resultantes de la base de clientes ayudarán al negocio a tomar mejores iniciativas hacia el mercado objetivo. Por ejemplo, si la tienda tiene un perfil de clientes de alto gasto, puede fortalecer su marketing ofreciendo programas de fidelización y promociones a este grupo de clientes.
Agrupamiento basado en densidad
El agrupamiento basado en densidad revela grupos similares identificando la densidad de puntos de datos. En particular, su diferencia distintiva de otros tipos es que evita hacer que los grupos tengan una forma o tamaño determinado en lugar de crear un número determinado de grupos. En este sentido, es útil en casos en los que las entidades de datos tienen un orden irregular al formar un grupo.
#Ejemplo de agrupamiento basado en densidad
Supongamos que un negocio está tratando de abrir nuevas tiendas y quiere identificar puntos calientes de clientes. Quiere mejorar la calidad de la nueva tienda minorista utilizando un algoritmo de agrupamiento basado en densidad.
El algoritmo puede identificar ubicaciones principales al distinguir áreas con intensaflujo de clientes, demografía de la población y actitudes de compra de esta población. De esta manera, los propietarios de negocios tienen datos valiosos que pueden utilizar al tomar decisiones sobre la apertura de la tienda.
Preguntas frecuentes sobre el análisis de grupos
Las preguntas más frecuentes sobre el análisis de grupos son sobre cuándo y cómo utilizar qué método de agrupamiento. Los usuarios nuevos a veces pueden encontrar confusión con respecto a la interpretación de los grupos. Por eso, las preguntas recopiladas aquí tienen como objetivo desentrañar de manera efectiva los matices importantes de la interpretación y prepararte para el análisis de datos.
Los cuatro tipos de análisis de clúster más comunes son el análisis de clúster jerárquico, el clúster de distribución, el clúster de partición y el clúster basado en la densidad. Aunque todos ellos tienen más o menos el mismo propósito, sus procesos de clusterización son diferentes entre sí.
Es cierto que, a primera vista, el análisis cluster destaca como un tipo de análisis cuantitativo, pero los algoritmos de éxito y los datos preestablecidos bien preparados demuestran que también puede utilizarse en el análisis cualitativo.
No, el muestreo por conglomerados y el análisis de conglomerados no son lo mismo. El muestreo por conglomerados es un proceso utilizado en la fase de recopilación de datos. Se utiliza para muestrear aleatoriamente un gran grupo de poblaciones. No es obligatorio en el análisis de conglomerados. Por otro lado, el análisis de conglomerados es un método de análisis de datos para identificar patrones similares y agruparlos.
Los mapas autoorganizados, los métodos basados en gráficos y los métodos basados en cuadrículas también son métodos valiosos que puede utilizar en el reconocimiento de patrones de conglomerados.
Como es sabido, el análisis cluster no recopila datos. En su lugar, crea un modelo útil dividiendo sus datos en trozos y grupos con el algoritmo de clustering. Por lo tanto, usted mismo debe preparar los datos para el análisis cluster y prestar atención a algunos factores mientras lo hace.
- En primer lugar, encuentre los datos que se ajusten a su propósito.
- Estandarice los datos de acuerdo con la escala en la que los evaluará.
- Adapte los datos al programa de clustering que vaya a utilizar.
- Por último, haga que el programa clasifique los datos utilizando el algoritmo de clustering.
El análisis de los resultados de la agrupación es tan importante como la creación y el procesamiento de los datos. Puede inspeccionar visualmente los grupos (coloreados, agrupados o con forma) con la facilidad que proporciona el modelado. Evaluar los datos numéricos según el método con el que creó su modelización es el siguiente paso.
De este modo, determinará las características de cada grupo de conglomerados. Si sus datos también contienen características cualitativas, no olvide evaluar las relaciones entre patrones en consecuencia. Como resultado de estos pasos de análisis, podrá utilizar el análisis de conglomerados para su proceso de toma de decisiones.
Conclusión
En resumen, el análisis de clúster muestra su poder para revelar patrones utilizando diversas técnicas de modelado. Su alta dimensionalidad es un aspecto fuerte de ello. Este artículo intenta mostrar con ejemplos que el análisis de clúster en marketing y minería de datos es beneficioso para las empresas. Ya sea información cualitativa o predicciones cuantitativas, el análisis de clúster revela la relación entre ellas a través de una poderosa exploración de datos. Es decir, las empresas modernas se benefician de este tipo de análisis para seguir tendencias y revelar correlaciones que no son visibles a simple vista. Por lo tanto, debes comprender y aprovechar el análisis de clúster para mejorar tu negocio en un mundo donde los datos son tan valiosos como el oro.
Eso es, las empresas modernas se benefician de este tipo de análisis para seguir tendencias y revelar correlaciones que no son visibles a simple vista. Por lo tanto, debes comprender y aprovechar el análisis de clúster para mejorar tu negocio en un mundo donde los datos son tan valiosos como el oro.
Los autores
Investigado y escrito por
forms.app, tu creador de formularios gratuito
- Vistas ilimitadas
- preguntas ilimitadas
- notificaciones ilimitadas
Artículos relacionados

Una guía completa de métodos de análisis de datos
Árboles de decisión: Definición, tipos y ejemplos
Análisis de factores: Una guía completa
Redes neuronales y cómo usarlas en el análisis de datos
Análisis de regresión: Definición, tipos y ejemplos