Análise de cluster: Definição, tipos e exemplos
Résumez avec
A análise de cluster é uma ferramenta simples e eficaz para usar no ambiente empresarial. Ajuda a entender melhor dados quantitativos complicados ou às vezes qualitativos com métodos de modelagem detalhados. Ao contrário de outros tipos de análise, seu objetivo principal não é mostrar ou provar razões; é uma ferramenta auxiliar para revelar melhor o que está acontecendo.
Neste artigo, para examinar a análise de cluster em profundidade, o que é a análise de cluster será a primeira coisa a ser explicada. Em seguida, será explicado quais métodos/tipos você pode usar para realizar essa análise. Por fim, você pode obter informações mais precisas na seção de perguntas frequentes.
O que é a análise de cluster?
A análise de cluster é um método de processamento de dados multivariado usado para mostrar estatísticas. Seu objetivo é categorizar ou, em outras palavras, agrupar entidades.
Serve como um estágio fundamental e crucial na análise estatística de dados, bem como na mineração de dados. Mas também é possível usá-lo em diferentes áreas. Em particular, a análise de cluster na mineração de dados pode especificar características qualitativas e quantitativas, mostrando sua flexibilidade. É por isso que as empresas sempre usam a análise de cluster como parte de seus mecanismos de tomada de decisão.
O algoritmo da análise de cluster é bastante simples. Ele cria padrões visíveis agrupando entidades semelhantes juntas. No entanto, com essa característica, está longe de ser um tipo de análise detalhado. Por outro lado, fornecer dados precisos também tem um lugar importante aqui.
Quanto mais dados são adequados para o agrupamento, mais eficaz é o padrão de agrupamento formado. Portanto, seria uma boa ideia escolher os métodos e programas mais adequados para seu objetivo ao realizar a análise de cluster.
Tipos de análise de cluster
Escolher o algoritmo de clustering certo pode ser um pouco como tentativa e erro. Mas se houver uma sólida razão matemática para jurar por um em detrimento dos outros, então pode ser razoável. E o importante aqui é que o que pode funcionar como mágica para um conjunto de dados pode falhar com outro.
Uma variedade de métodos para análise de cluster abaixo é apresentada a você, cada um trazendo seu aspecto e abordagem únicos para a mesa. É como escolher a ferramenta certa para o trabalho e descobrir qual funciona com seu conjunto de dados. Agora, os quatro tipos mais conhecidos são apresentados a você com exemplos de análise de cluster:
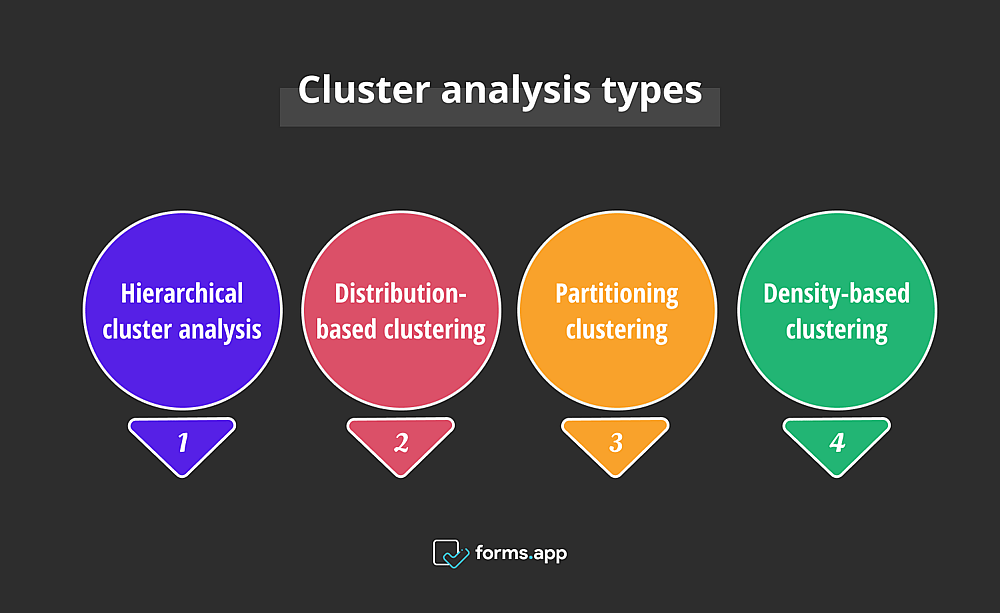
Tipos de análise de cluster
Análise de cluster hierárquica
Neste método, o algoritmo organiza o agrupamento das entidades de dados fornecidas em uma ordem hierárquica. A formação de clusters ocorre a partir de um único cluster e dividindo-o em clusters separados.
A ordem da hierarquia entre esses clusters pode variar dependendo do objetivo de sua classificação e do método de modelagem. Você pode usar principalmente duas abordagens diferentes para o cluster hierárquico:
- Método aglomerativo: É um processo de baixo para cima que começa com uma única entidade e faz grupos de cluster a partir dela.
- Abordagem divisiva: É um processo de cima para baixo que começa com entidades no mesmo cluster e faz grupos de cluster dividindo-os.
#Exemplo de análise de cluster hierárquica
Imagine uma empresa de tecnologia lançando um novo dispositivo doméstico inteligente. A empresa quer usar a análise de cluster hierárquica para entender como os potenciais clientes responderão a esse novo produto. Dados como idade, renda, nível de educação, etc., são coletados para análise.
A análise hierárquica começa a criar clusters de acordo. Por exemplo, é formado um cluster como jovens e aqueles com altos rendimentos, e este grupo pode ser exatamente o público-alvo que você está procurando.
Agrupamento baseado em distribuição
Este modelo de agrupamento mostra a distribuição de entidades de dados inter-relacionadas no gráfico. Os Modelos de Mistura Gaussiana são um exemplo típico deste tipo. Sua área de uso é agrupar estruturas conectadas entre si com estruturas complexas mais facilmente.
#Exemplo de agrupamento baseado em distribuição
Suponha que uma empresa de provedores de internet queira entender os padrões de cancelamento de clientes para intervir neles. Em primeiro lugar, deve haver um conjunto de dados incluindo informações como satisfação geral ou específica do cliente, preferências de pacote de internet, taxas de compromisso e respostas.
Então, você usa o algoritmo de agrupamento baseado em distribuição e espera que ele revele o padrão entre esses valores. Por exemplo, se a taxa de vendas for baixa em um grupo que é contatado muito para renovar compromissos de internet, este e outros padrões semelhantes constituem um exemplo de cancelamento atual e futuro.
Agrupamento por partição
Ao contrário do agrupamento baseado em distribuição, a partição divide as entidades de dados em seções não-sobrepostas. Assim, cada parte que ela divide se torna um cluster. Esses clusters podem ser usados para separar uns dos outros para um propósito específico. Para implementar uma partição como esta, o método K-Means é mais comumente usado.
- Agrupamento K-means: O agrupamento K-means classifica seu conjunto de dados em clusters predeterminados. O algoritmo coloca aleatoriamente centros de cluster e começa a classificar as entidades de dados em torno desses centros. Em seguida, é calculada a média desses centros e é criado um novo centro. Esse processo pode ser repetido muitas vezes, resultando em clusters não sobrepostos.
#Exemplo de agrupamento por partição
Imagine uma loja em um cenário de venda no varejo tendo dificuldades com sua estratégia de marketing. Optar pelo agrupamento por partição é o primeiro passo na pesquisa de mercado. Os algoritmos de aprendizado de máquina identificarão grupos como grupos de clientes e segmentos de mercado de acordo com as partições predefinidas.
Os padrões resultantes da base de clientes ajudarão o negócio a tomar melhores iniciativas em relação ao mercado-alvo. Por exemplo, se a loja tiver um perfil de cliente de alto gasto, pode fortalecer seu marketing oferecendo programas de fidelidade e promoções para esse grupo de clientes.
Agrupamento baseado em densidade
O agrupamento baseado em densidade revela grupos semelhantes identificando a densidade de pontos de dados. Em particular, sua diferença distinta de outros tipos é que ele evita tornar os clusters de uma determinada forma ou tamanho, em vez de criar um número específico de clusters. Nesse sentido, é útil em casos em que as entidades de dados têm uma ordem irregular ao formar um cluster.
#Exemplo de agrupamento baseado em densidade
Suponha que um negócio esteja tentando abrir novas lojas e queira identificar pontos de interesse dos clientes. Ele deseja aprimorar a qualidade da nova loja de varejo usando um algoritmo de agrupamento baseado em densidade.
O algoritmo pode identificar locais privilegiados distinguindo áreas com intenso fluxo de clientes, demografia da população e atitudes de compra desta população. Dessa forma, os proprietários de negócios têm dados valiosos que podem usar ao tomar decisões sobre a abertura da loja.
Perguntas frequentes sobre análise de cluster
As perguntas mais frequentes sobre análise de cluster são sobre quando e como usar qual método de agrupamento. Novos usuários às vezes podem encontrar confusão em relação à interpretação dos clusters. Por isso, as perguntas coletadas aqui têm como objetivo desvendar efetivamente nuances importantes de interpretação e prepará-lo para a análise de dados.
Os quatro tipos de análise de clusters mais comuns são a análise de clusters hierárquicos, o clustering de distribuição, o clustering de partição e o clustering baseado na densidade. Embora todos eles tenham mais ou menos o mesmo objetivo, os seus processos de agrupamento são diferentes uns dos outros.
É verdade que, à primeira vista, a análise de clusters se destaca como um tipo de análise quantitativa, mas os algoritmos bem sucedidos e a preparação adequada dos dados mostram que também pode ser utilizada na análise qualitativa.
Não, a amostragem por conglomerados e a análise de conglomerados não são a mesma coisa. A amostragem por conglomerados é um processo utilizado na fase de recolha de dados. É utilizada para amostrar um grande grupo de populações de forma aleatória. Não é obrigatória na análise de clusters. Por outro lado, a análise de clusters é um método de análise de dados que permite identificar padrões semelhantes e agrupá-los.
Os mapas auto-organizáveis, os métodos baseados em gráficos e os métodos baseados em grelhas são também métodos valiosos que pode utilizar no reconhecimento de padrões de clusters.
Como é sabido, a análise de clusters não recolhe dados. Em vez disso, cria um modelo útil, dividindo os dados em partes e grupos com o algoritmo de agrupamento. Por conseguinte, deve preparar os dados para a análise de clusters e prestar atenção a alguns factores ao fazê-lo.
- Em primeiro lugar, encontre os dados que se adequam ao seu objetivo e crie uma base de dados completa e detalhada.
- Padronize os dados de acordo com a escala em que os vai avaliar.
- Adapte os seus dados de acordo com o programa de agrupamento que vai utilizar.
- Por fim, faça com que o programa classifique os dados utilizando o algoritmo de agrupamento.
A análise dos resultados do cluster é tão importante quanto a criação e o processamento de dados. É possível inspecionar visualmente os grupos (coloridos, agrupados ou em forma) com a facilidade proporcionada pela modelação. A avaliação dos dados numéricos de acordo com o método pelo qual a modelação foi criada é o passo seguinte.
Desta forma, determina-se as características de cada grupo de clusters. Se os dados também contiverem características qualitativas, não se esqueça de avaliar as relações de padrão de acordo com elas. Como resultado destas etapas de análise, será capaz de utilizar a análise de clusters no seu processo de tomada de decisão.
Conclusão
No geral, a análise de cluster mostra seu poder para revelar padrões usando várias técnicas de modelagem. Sua alta dimensionalidade é um forte aspecto dela. Este artigo tenta mostrar com exemplos que a análise de cluster em marketing e mineração de dados é benéfica para empresas. Seja insights qualitativos ou previsões quantitativas, a análise de cluster revela a relação entre eles através de poderosa exploração de dados.
Isso significa que as empresas modernas se beneficiam desse tipo de análise para acompanhar tendências e revelar correlações que não são visíveis à primeira vista. Portanto, você deve entender e se beneficiar da análise de cluster para melhorar seu negócio em um mundo onde dados são tão valiosos quanto ouro.
Os autores
forms.app, seu criador de formulários gratuito
- Visualizações ilimitadas
- número ilimitado de perguntas
- notificações ilimitadas
Postagens relacionadas

Um guia completo para métodos de análise de dados
Árvores de decisão: Definição, tipos e exemplos
Análise de Fatores: Um guia abrangente
Redes neurais e como usá-las na análise de dados
Análise de regressão: Definição, tipos e exemplos